
PracticeEveryday
개념적 데이터 모델링 본문
개념적 데이터 모델링
- 우리가 파악한 업무에서 개념을 뽑아내는 과정
- 일을 하는 순서와 공부를 하는 순서는 다를 수 있다.
※ 개념적 모델링이 논리적, 물리적 모델링보다 앞선 단계이지만, 논리적 물리적 모델링을 경험해보지 않은 사람이
개념적 모델링을 할 수는 없다.
- 다음 단계를 위한 요소들을 추출해내는 과정이기 때문에 관계형 데이터베이스 모델링의 가장 중요한 부분이다.
- 첫 단추를 잘 꿰면 다음 수순은 물 흐르듯이 진행될 수가 있다.
※ 필터 : 현실에서 개념을 추출해내는 도구
※ 언어 : 개념에 대해 다른 사람과 대화 할 수 있는 도구
- 아래의 ERD가 필터이자 언어로서의 도구이다.
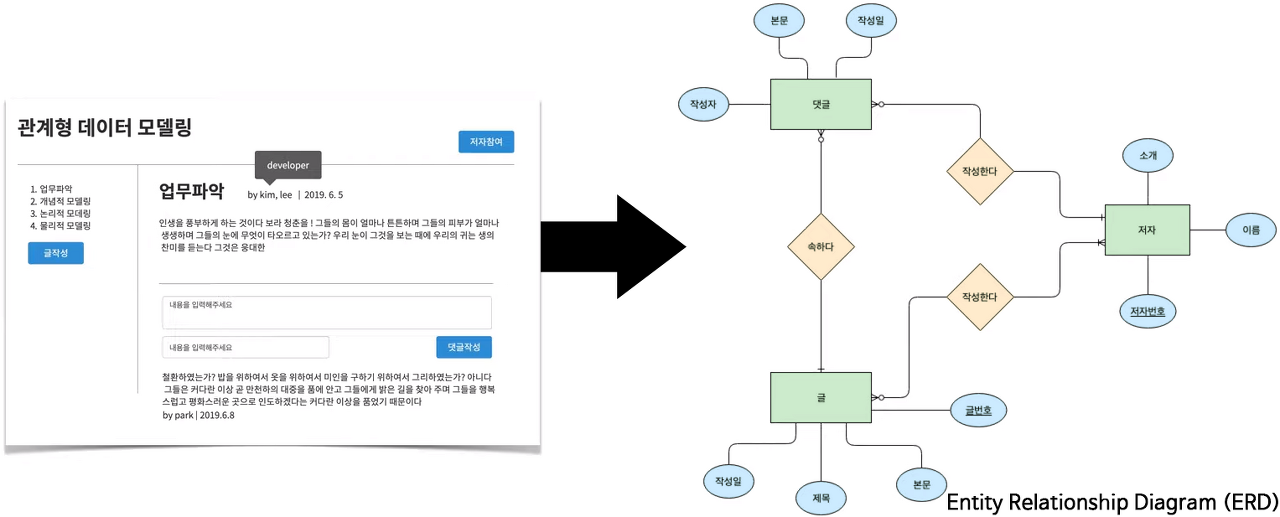
※ Entity Relationship Diagram ( ERD )
- 개념적 데이터 모델링의 도구이자, 결과물이다.
- 현실의 복잡성을 극복하고, 문제를 3가지의 관점으로 바라본다.
1. 정보 (●) : 정보를 발견하고 표현한다.
2. 그룹 (■) : 서로 연관된 정보를 인식하고 묶어 표현한다.
3. 관계 (◆) : 그룹 사이의 관계를 인식하고 표현한다.
- 현실로부터 개념을 인식하는 도구이면서, 다른 사람도 알 수 있도록 표현하는 도구이다.
- 매우 쉽게 표 ( RDB Diagram, 다음 단계인 논리적 모델링에서 작성 )로 전환할 수 있으며 오랜 시간 정교한 규칙들이
정립되어 왔다.
관계형 데이터베이스다운 개념의 구조
1. 개념 추출
- 기획서에서는 여러가지 정보들이 흩어져있다.
- 여기에서 연관된 정보를 묶어주는 큰 덩어리부터 추출한다.

- 이걸 어떻게 표현하는 지에는 정답이 없다.
- 설명이 가능하며 모순이 없다면 모두 타당하다! 하지만 필요한 정보는 모두 가져야 한다!
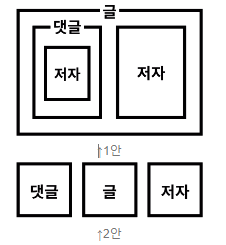
- 그 중에서 관계형 데이터베이스에 더 잘 어울리는 모델이 유리하므로 2안을 선택하자!
※ 관계형 데이터베이스에 더 잘 어울리는 모델?

- 이 모델을 설명하기 위한 표는 아래와 같다.

- 표안에 작은 표가 중첩 ( Nested ) 되어 있는 형태이다.
=> 하지만! RDB는 이러한 내포관계를 허용하지 않는다.

- 보이도록 원하는 대로 구현했지만 개념들의 관계가 가시적으로 보이기는 힘들다.
- 초 거대 프로젝트라도 어떻게든 구현은 가능하지만, 알아보기 힘들며 유지 / 보수도 힘들다.
- 프로젝트가 거대해지면, Column이 1천개가 넘을 수도 있다.
=> 데이터를 원할 때, 1천 개의 Column에 Access되므로 굉장히 비효율적이다.
=> 굉장히 많은 중복 row가 발생할 수도 있다. 당장 위의 테이블도 저자 1의 내용이 중복으로 저장되어 있다.
=> 저장 뿐아니라, 입력, 수정도 중복으로 행해져야 한다.
※ 거대 단일 Table로 표현하면, 중복이 발생하게 된다!!


- 주제에 따라 Data를 Grouping 할 수 있다.
- 조회하려는 대상만 조회가 가능하므로 컴퓨터의 자원을 아낄 수가 있다.
- JOIN이 가능하다.
SELECT 댓글.내용, 댓글.작성일, 저자.이름, 저자.소개 FROM 댓글 LEFT JOIN 저자 ON 댓글.저자아이디 = 저자.아이디
- JOIN으로 표현이 가능하므로, 저장되는 데이터의 중복을 피할 수 있다.
- 관계형 데이터베이스에는 언제든지 필요할 때마다 표끼리 합성해 낼 수 있다.
=> 그로므로 내포된 형태의 완성된 표가 아닌, 평면적인 형태의 개별적인 표를 서로 참조시켜서 사용한다.
ERD 구성 요소
1. Entity ( 개념, 개체 )

- 개념적 모델링 및 ERD에서, 이러한 모델의 구성 요소 ( 큰 덩어리 )를 Entity라고 한다.
- 이 Entity는 후에 DB에서 TABLE로 전환될 것이다.
- ' 글 ' Entity를 가져와 보자
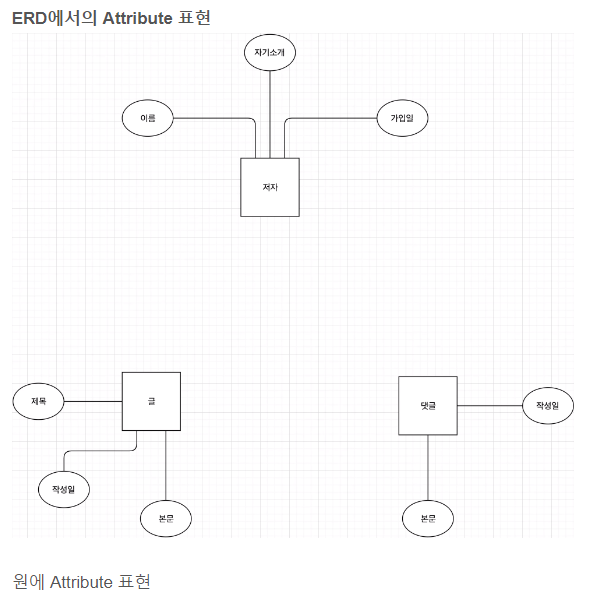
2. Attribute ( 속성 )

- 이 ' 글 ' Entity는 실제 Data가 아니다.

- 구체적인 Data는 제목, 생성일, 본문, ... 이다. 이런 각각의 Data들이 모여 Entity를 이루게 된다.

- 이런 Data를 Grouping 한 것이 Entity가 된다.
- 이 구체적인 Data는 Attribute( 속성 ) 이라고 한다.
- Attribute는 후에 TABLE의 COLUMN이 된다.
※ 그럼 저자명, 댓글은 왜 글의 Attribute가 되지 않는가?
- 글 아래에 ' 저자명 ' 속성 하나만 필요하다면 Attribute 속성이 될수 있지만 저장명 외에도 저자 아래에
저자소개도 함께 필요하게 된다.
=> 즉, 이런 저자에 대한 Data가 여럿이고, 이것들이 하나의 Entity가 된다.
- Entity는 하위 Entity를 두지 않으며 ( => 중첩 테이블, Nested 하게 두지 않으며 )
Entity는 개별적으로 존재( 저장 )하고 필요할 때마다 JOIN을 통해 합한 결과를 이용할 것이다.
- 그러므로 모델링에서는 별개의 것으로 보면 된다.
3. Relation ( 관계 )
- Entity들 간의 관계

- 글은 저자가 쓴것
=> 글에 댓글이 포함되어 있다.
- 댓글은 저자가 쓴 것
=> 이러한 Entity 사이의 관계가 Relationship ( 관계 )
- 논리적 데이터 모델링에서 Entity에 포함시키고 싶은 다른 Entity의 Primary Key ( PK, 기본키 )를
Foreign Key (FK, 외래키 )로 두고 SQL문의 JOIN 기능을 사용하여 이 FK를 조건으로 일치하는 PK를 가진
data를 해당 Entity에서 참조해서 사용한다.
ERD의 구성 요소
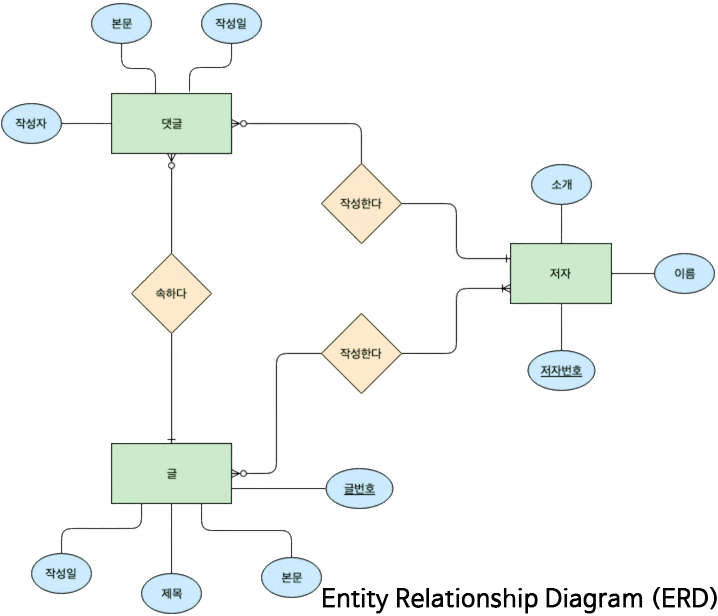
*Entity(■): data의 group
ㆍDatabase의 TABLE이 된다.
*Attribute(●): data
ㆍTABLE의 COLUMN이 된다.
*Relationship(◆): Entity간의 관계
ㆍTABLE의 COLUMN 중 Foreign Key(FK)로 다른 TABLE의 Primary Key(PK)가 오게 된다.
- ERD에는 속하지 않지만, 표의 행 ( Row )에 속하는 인스턴스인 Tuple이 존재한다.
30세 남성인 홍길동 => 테이블의 ROW가 된다.
- 개념적 데이터 모델링은 " 개념 "에 집중하여, DB 체계와는 거리를 두고 있기 때문에, 용어들이 실제 DB에서
사용하는 용어와는 다르다.
Entity 정의
- 현실과 Data의 서로 원인 - 결과 관계
Application을 하나의 건물이라고 할 때
- UI ( User Interface )가 옥상이라면 DB ( DataBase )는 지하이다.
UI와 DB 사이의 일들을 원인 - 결과의 관점으로 생각해보자.
- UI에 Data를 입력하는 원인으로 DB의 Data를 변경하는 결과를 낳는다.
- DB의 Data라는 원인으로, UI에 내용이 표시되는 결과를 낳는다.
=> 즉, 사용자가 마주하는 UI ( 현실 )과 컴퓨터 ( DB )에 저장되는 데이터는
서로 원인과 결과의 관계에 있다고 할 수 있다.
=> 이 원인과 결과를 번갈아가며 순차적으로 점검해야 좋은 모델링이 될 수 있다.- 기획자와 구현자가 다르다면 데이터 모델링까지는 함께 동행하는 것이 이상적이라 생각한다.
- 기획과 데이터 모델링은 사소한 부분까지 서로 놓치면 안되는 중요한 작업이다.
1. 가장 먼저 해야할 일은, 기획서에서 Entity를 찾아내는 것이다.
※ 팁으로 읽기 UI 보다는 쓰기 UI에서 Entity를 찾아내기가 더 쉽다.

Entity Relationship Diagram 작성 ( https://www.draw.io )

- 사각형에 Entity를 표현
2. Attribute 정의
- Attribute ( 속성 )는 각 Entity의 소속이 될 Data 종류이다. ( Column에 위치한다. )
=> 이 역시 쓰기 UI에서 쉽게 파악 가능하다.
- 글 Entity에서 " Entity 저자 "가 Dropbox에서 선택하는 것은 단독 Data가 아니라 좀 더 복합적이라 별도의 Entity로
독립해 나갈 있을 수 있다는 것이다.
- 그래서 Attribute라기보다는, Relationship으로 연결한다.
- 쓰기 UI만으로는 부족한 정보가 있을 수 있다.
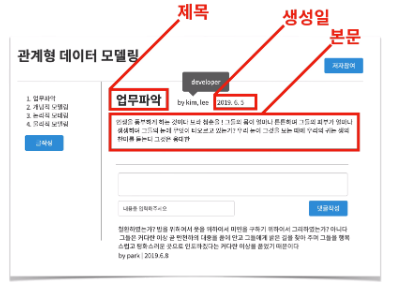
- 읽기 UI로 보면 글의 " 생성일 " 이 보인다.
- 쓰기 UI에서 별도의 지정없이 자동으로 현재 시각을 계한하여 포함하는 Data이기 때문이다.
- 이런 정보들도 빠뜨리지 않아야 한다!!
- UI를 토대로 모델링을 하다보면, UI가 모델링을 검증하고 모델링이 UI를 검증하는 형태의 교차 검증이
이루어질 수 있다. ( 기획에서 모델링이 이어지고, 모델링하면서 부족했던 기획을 보충할 수 있다. )
- 그러므로 기획자와 구현자가 한 사람이 아니라면 개념적 모델링까지는 함께 해야 좋은 결과를 얻을 수 있다.
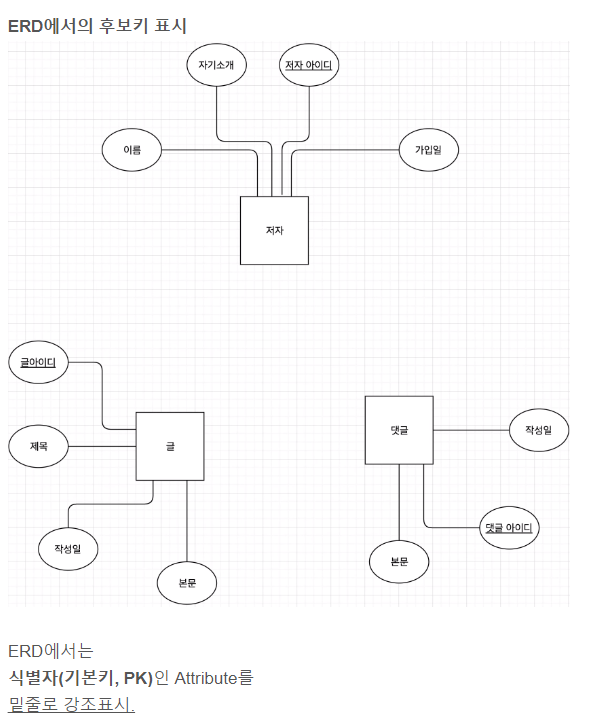
3. Identifier ( 식별자 ) 지정
- 이제 Entity의 Attribute 중에 대표적인 Identifier ( 식별자 )를 뽑아야 한다.
- Attribute들 중에 식별자가 될 수 있는 후보가 없다면 새로 추가해야 한다.
Ex 주민등록번호, 차량번호, 웹사이트의 도메인 이름 등...
- 원하는 대상 ( 인스턴스 . 개체 )를 정확하게 가리킬 수 있어야 한다.
=> 즉, 중복될 수 없는 값을 가지기 때문에, 인스턴스 간에 구분이 가능하다.
=> 그 대상을 제외한 누구도 같은 값을 가질 수 없는 것이 가장 중요하다.
- 이렇게 지정한 Identifier는 DB에서 Primary Key ( PK, 기본키 )가 될 것이다.
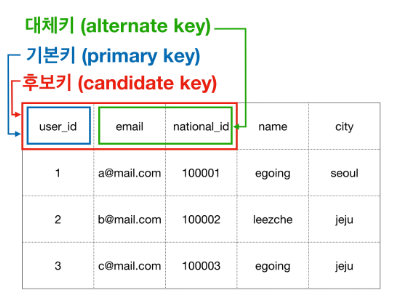
- Name과 City는 중복이 발생할 수 있으므로 후보에서 제외한다.
- User_id, Email, National_id는 각각 중복되지 않는 값을 가지므로, Identifier의 후보가 될 수 있으며, 이들을
후보키 ( Candidate Key )라고 한다.
- 그 중 식별자로 지정한 것을 기본키 ( Primary Key )라고 한다.
- 그 외 나머지 후보키는 대리키 ( Alternate Key )라고 한다.
- 대리키는 필요한 때에, 성능 향상을 위해서 기본키가 아닌 Secondary Index로 지정하기 좋다.
- 복합키 ( Composite Key )
- 단일 Attribute로는 중복이 발생할 수 있지만, 여러 Attribute가 함께 사용된 결과는 중복이 발생할 수 없을 때
( 식별 가능할 때 ) 이 묶음 단위를 복합키 ( Composite Key )로 사용할 수 있다.
- 인조키 ( Artificial Key )
- 자연키 ( Natural Key )로는, 즉, 자연스럽게 존재하는 Atrribute들로는 식별자를 선택할 수 없을 때
인조키 ( Artificial Key )를 추가하여 사용할 수 있다.
※ DB에서는 SEQUENCE를 사용하거나 AUTO_INCREMENT 속성을 가진 INT를 사용하여 자동으로 1씩 증가하여
중복되지 않는 값이 매겨지도록 설정할 수 있다.
4. Entity간의 연결 ( Relationship )

- 각 표들이 연결된 상태로써 위와 같이 표들관의 관계를 이야기한다.
- 왜래 ( Foreign )에 있는 TABLE ( 저자 TABLE )과 연결한다.
- 이러한 외래의 식별자를 자기 TABLE ( 글 TABLE, 댓글 TABLE )에서는 외래키 ( Foreign Key, FK )라고 한다.
=> 즉 DB에서 Primary Key와 Foreign Key를 통해 Entity간의 Relationship이 구현된다.

5. Cardinality ( 집합론에서 집합의 " 크기 " )

- " 저자 "의 입장에서, 댓글은 여러개를 가질 수 있다. ( 한 명이 여러 댓글을 작성할 수 있다. )
=> ? : N의 관계가 된다.
- " 댓글 " 입장에서, 저자는 하나만 가질 수 있다. ( 본 댓글은 한 명이 작성한 것이다. )
=> 1: ?의 관계가 된다.
- 합치면 1 : N의 관계가 된다.
- ERD에서는 Relation의 양 긑이 다음과 같이 표현된다.

- 1인 쪽이 일직선, N인 쪽이 세 갈래 선으로 표현된다.
- 선의 끝에 1, N이라고 표시하기도 한다.

- " 담임 "의 입장에서, 반은 하나 가질 수 있다. ( 본 담임은 한 반만 담당할 수 있다. )
=> ? : 1의 관계가 된다.
- " 반 "의 입장에서, 담임은 하나 가질 수 있다. ( 본 반의 담임은 한 명만 될 수 있다. )
=> 1 : ?의 관계가 된다.
- 합치면, 1 : 1의 관계가 된다.
- ERD에서는 Relation의 양 끝이 다음과 같이 표현된다.

- 둘다 1이라 양 쪽이 모두 일직선으로 표현된다.

- " 저자 "의 입장에서, 글은 여러 개 가질 수 있다. ( 한 명이 여러 글을 작성할 수 있다. )
=> ? : M 관계가 된다.
- " 글 "의 입장에서, 저자는 여러 개 가질 수 있다. ( 본 글은 여러 명이 작성했을 수 있다. )
=> N : ? 관계가 된다.
- 합치면 N : M의 관계가 된다.
- ERD에서는 Relation의 양 끝이 다음과 같이 표현된다.

- 둘 다 여러 개이므로, 양 쪽이 모두 세 갈래 선으로 표현된다.
- 선의 끝에 N, M이라고 표시하기도 한다.
- N : M의 경우, DB의 TABLE 끼리만으로는 표현이 불가능하기 때문에, 신규 테이블에서 양쪽 TABLE의 FK를 사용하여
양쪽을 참조하는 형태 ( 연결 TABLE )를 만들어 사용한다.
=> 즉, 연결 TABLE에서 1 : N, 1 : M으로 하여 구현한다.
6. Optionality ( 선택성 )
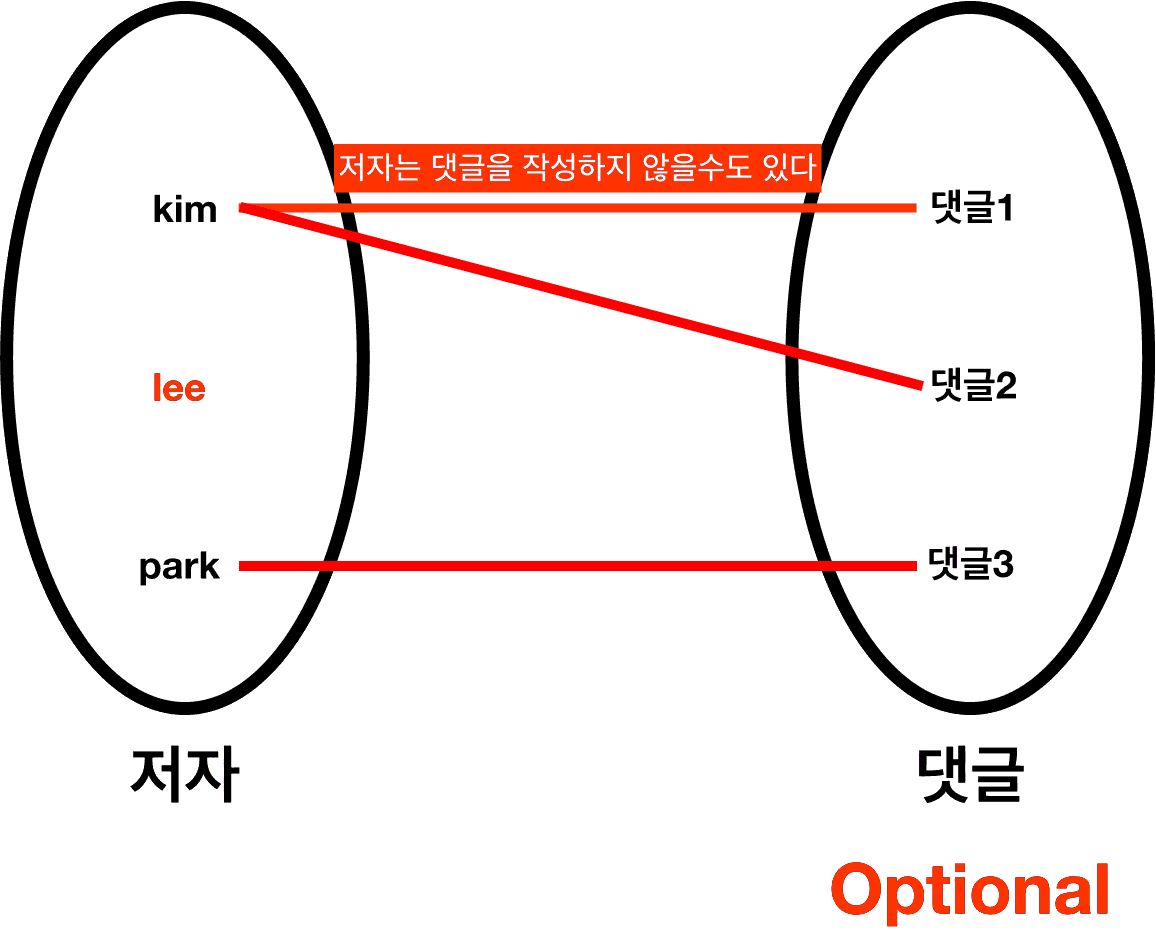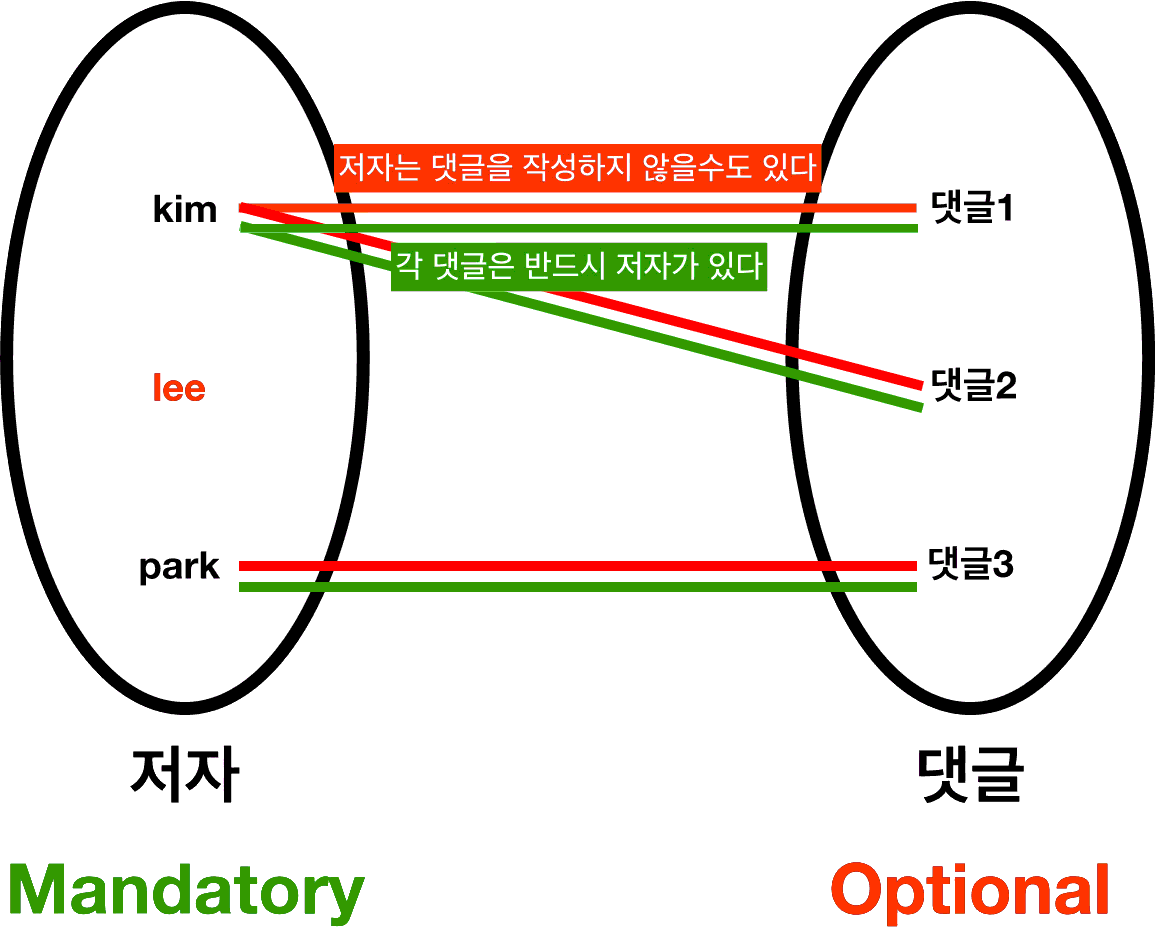
- " 저자 "의 입장에서 " 댓글 "은 필수로 존재해야 하나요?
=> 아니요 : Optional ( 선택적인 )
- " 댓글 "의 입장에서 " 저자 "는 필수적으로 존재해야 하나요?
=> 예 : Madatory ( 필수적인 )
- ERD에서는 Relation의 양 끝이 다음과 같이 표현된다.

- Optional인 부분에 원형이 매겨진다.
- Madatory인 부분에 수직선이 매겨진다.
Optionality는 Cardinality와 별개의 속성이다.
- Optionality는 개념에 따라 다를 수 있다.
Entity를 " 선생님 "으로 한다면 " 반 "은 Optional이 되지만
Entity를 " 담임선생님 "으로 한다면 " 반 "은 Mandatory가 된다.
Optionality는 현실에 따라 다를 수 있다.
- " 학생 " Entity와 " 967회 모의 TOEIC 답안 " Entity를 보면
" 제출답안 " 입장에서는 " 학생 " 하나만 가질 수 있고 ( 본 제출답안의 작성자는 한 사람 ),
" 학생 " 입장에서도 " 특정 시험 "의 " 제출 답안 "은 하나만 가질 수 있다. ( 여러개 칠 수 없고, 여러개 낼 수 없다. )
" 제출답안 " 입정에서는 존재하기 위해 " 학생 "은 필수적이다 ( Mandatory )
" 학생 " 입장에서는 시험을 치르지 않았을 수도 있다. " 제출 답안 "은 필수가 아니다 ( Optional )
Cardinality는 1:1 관계이지만, 반드시 Mandatory:Mandatory로 이어지지 않는다.
이렇게 현실에서는 다양한 종류와 문제들이 존재할 수 있다!
RDB Modeling - 3. 개념적 데이터 모델링
RDB Modeling (관계형 데이터베이스 모델링) 3. 개념적 데이터 모델링 3.1 - 개념적 데이터 모델링 소개 3.2 - 관계형 데이터베이스다운 개념의 구조 3.3 - ERD의 구성요소 3.4 - Entity 정의 3.5 - Attribute..
ydeer.tistory.com
'DB' 카테고리의 다른 글
| TypeORM (0) | 2022.08.13 |
|---|---|
| 논리적 데이터 모델링 (0) | 2022.08.09 |
| RDB Modeling (0) | 2022.08.08 |
| Key (0) | 2022.05.13 |
| Transaction (0) | 2022.05.11 |



